Ramón Del Villar & Gilbert García – Ingeniería en Ciencias de la Computación, Pontificia Universidad Católica Madre y Maestra (PUCMM)
Introducción
En la República Dominicana se han observado fluctuaciones significativas en los precios de productos básicos de la canasta familiar. Estos vaivenes de precios generan preocupación en consumidores y autoridades, ya que afectan el poder adquisitivo de los hogares y crean incertidumbre en productores y comerciantes. Diversos factores contribuyen a estas variaciones: la estacionalidad (por ejemplo, ciertas cosechas agrícolas encarecen fuera de temporada), factores macroeconómicos como la inflación general y los cambios en la tasa de cambio del dólar, además de dinámicas de mercado (oferta, demanda e incluso especulación). En conjunto, estos elementos dificultan predecir los precios futuros de alimentos esenciales, complicando la planificación financiera de las familias y la toma de decisiones de las autoridades regulatorias.
Frente a esta problemática, surge la necesidad de una solución proactiva que permita anticipar las variaciones de precios de productos básicos de forma eficiente. Actualmente, las instituciones locales (por ejemplo, Pro Consumidor y el Ministerio de Industria y Comercio) monitorean y publican precios de alimentos en tiempo real mediante plataformas digitales; sin embargo, dichas iniciativas se enfocan en la transparencia del precio actual más que en la predicción de su comportamiento futuro. Es decir, los consumidores pueden consultar en línea los precios vigentes de una gran variedad de productos (a través de herramientas como el Sistema Dominicano de Información de Precios, SIDIP), lo que mejora la información disponible, pero no se cuenta con alertas ni pronósticos sobre cómo podrían evolucionar esos precios en las próximas semanas. Este proyecto de investigación se enfoca precisamente en cubrir ese vacío, desarrollando un modelo predictivo de precios empleando análisis de series temporales para reducir la incertidumbre y fomentar una mayor anticipación en el mercado de alimentos básicos.
El trabajo ha sido realizado como proyecto de grado por estudiantes de Ingeniería en Ciencias de la Computación de la PUCMM. El objetivo general es claro y de alto impacto social: crear un sistema capaz de pronosticar los precios futuros de productos esenciales de la canasta básica dominicana a partir de datos históricos, de manera que distintos actores puedan tomar decisiones informadas. En términos sencillos, se busca dotar a los consumidores de una herramienta que les indique si un producto tenderá a subir de precio (para adelantarse en la compra) o bajar (para planificar sus gastos), al mismo tiempo que las autoridades podrían detectar con anticipación alzas anómalas y los comerciantes ajustar sus inventarios con menor riesgo. A continuación, se presentan los detalles del problema abordado, la metodología seguida y los resultados obtenidos en el desarrollo de este sistema predictivo.
Problemática y Estado del Arte
La volatilidad en los precios de alimentos básicos –como el arroz, las habichuelas, los huevos o el pollo– es un desafío persistente en la economía dominicana. Los consumidores de ingresos medios y bajos son especialmente vulnerables a cambios abruptos de precios, ya que dificultan la organización de presupuestos familiares y pueden traducirse en menor acceso a productos de primera necesidad. Por ejemplo, incrementos repentinos en el precio del arroz o las habichuelas impactan de inmediato la canasta básica, obligando a las familias a reasignar gastos o incluso a prescindir de ciertos alimentos. A nivel de mercado, los comerciantes y pequeños productores también enfrentan incertidumbre: la falta de previsibilidad en los precios complica decisiones sobre cuánto stock comprar o producir, y puede ocasionar pérdidas si los precios caen inesperadamente luego de haber almacenado producto costoso. Estudios a nivel internacional han confirmado que este tipo de volatilidad de precios de alimentos puede amenazar la seguridad alimentaria y la estabilidad económica en países en desarrollo. En particular, se han observado patrones de alta volatilidad asociada a factores externos (clima, mercados globales) y periodos inflacionarios, los cuales afectan negativamente tanto a consumidores como a productores [1]. Resolver esta problemática permitiría aliviar la carga económica en los hogares y mejorar la eficiencia en la regulación del mercado interno.
En respuesta a la volatilidad de precios, diversos países de Latinoamérica han implementado iniciativas orientadas a la transparencia del mercado. Por ejemplo, en México la Procuraduría Federal del Consumidor lanzó la plataforma “Quién es Quién en los Precios” para informar diariamente el costo de la canasta básica en distintos establecimientos, mientras que en Chile existen observatorios de precios en línea para monitorear productos de primera necesidad. En República Dominicana, Pro Consumidor puso en marcha el SIDIP, un sistema en línea que permite comparar precios en tiempo real de una amplia variedad de alimentos en supermercados y mercados del país. Estas plataformas gubernamentales brindan a los ciudadanos información actualizada y fomentan la competencia, al permitir identificar dónde comprar más barato. Sin embargo, la mayoría de estas soluciones no incorporan modelos de predicción para estimar valores futuros; se limitan a informar los precios actuales o históricos. Esto deja una brecha importante: la disponibilidad de datos abiertos ha mejorado la visibilidad del mercado, pero aún hace falta dar el salto hacia la analítica predictiva para convertir esos datos en alertas o proyecciones útiles a futuro. Es aquí donde nuestro proyecto se posiciona, al proponer una herramienta que no solo muestre el precio de hoy, sino que anticipe el de mañana.
En cuanto a enfoques técnicos para predecir precios, la literatura especializada ofrece varios caminos. Un método estadístico tradicional ampliamente utilizado es el ARIMA (AutoRegressive Integrated Moving Average), propuesto originalmente por Box y Jenkins en la década de 1970. Modelos ARIMA y sus variantes han sido aplicados con éxito en la predicción de precios agrícolas y alimenticios en diversos estudios clásicos, logrando capturar patrones estacionales y tendencias cíclicas presentes en las series temporales de precios. Por ejemplo, Jadhav et al. (2017) demostraron la utilidad del modelo ARIMA para pronosticar los precios de cultivos básicos (arroz, mijo, maíz) en mercados locales de la India [4]. Estos enfoques puramente estadísticos brindan una línea base sólida al capturar componentes históricos recurrentes en las series de tiempo, y resultan especialmente relevantes cuando la dinámica de precios es relativamente estable y lineal. De hecho, en contextos donde las variaciones de
precios siguen patrones regulares (por ejemplo, incrementos estacionales predecibles), modelos lineales como ARIMA o su extensión estacional SARIMA pueden alcanzar una precisión competitiva con métodos más complejos [7]. Es importante mencionar también que la evaluación de supuestos, como la estacionariedad de la serie, es crucial al emplear ARIMA; pruebas estadísticas como Dickey-Fuller se utilizan para verificar la presencia de raíces unitarias y garantizar la validez del modelo [9].
Paralelamente, los avances en aprendizaje automático y técnicas de inteligencia artificial han abierto nuevas posibilidades para la predicción de series temporales complejas. En años recientes han cobrado protagonismo las redes neuronales recurrentes, en particular las de tipo LSTM (Long Short-Term Memory). Las redes LSTM fueron introducidas por Hochreiter y Schmidhuber en 1997 como una arquitectura capaz de aprender dependencias de largo plazo en secuencias, superando el problema de desvanecimiento del gradiente presente en las redes recurrentes simples [8]. Aplicadas a series de precios, las LSTM pueden en teoría capturar relaciones no lineales y efectos retardados que los modelos estadísticos tradicionales no consiguen modelar fácilmente [6]. Investigaciones recientes indican que los modelos basados en LSTM logran un desempeño muy competitivo –e incluso superior– en escenarios de alta volatilidad o con datos muy ruidosos [5]. Por ejemplo, Yang et al. (2023) emplearon una LSTM para predecir el precio de la carne de cerdo durante periodos de alta incertidumbre (pandemia de COVID-19) y hallaron que este modelo superó a un ARIMA equivalente tanto en predicciones de corto como de largo plazo, reduciendo significativamente el error de pronóstico [5]. Este resultado concuerda con otros estudios en los que las LSTM han capturado dinámicas no lineales sutiles en precios agrícolas, adaptándose mejor a cambios bruscos que los modelos lineales [6], [11]. No obstante, la eficacia de las redes neuronales depende de contar con suficientes datos para entrenamiento y de ajustar correctamente sus hiperparámetros; en contextos con series muy cortas o con patrones predominantemente lineales, métodos clásicos pueden seguir siendo la opción más robusta [7].
Otra vertiente relevante en el estado del arte son los enfoques híbridos que combinan modelos estadísticos y de aprendizaje profundo. En la literatura se han explorado sistemas que buscan aprovechar lo mejor de ambos mundos: por ejemplo, usar un ARIMA para modelar la estructura lineal básica de la serie, y luego aplicar una red neuronal sobre los residuos para capturar patrones no lineales restantes. Pandit et al. (2023) evaluaron modelos híbridos ARIMAX (ARIMA con variables exógenas) combinados con distintas técnicas de inteligencia artificial para pronosticar índices de rendimiento de cultivos en India, encontrando que la inclusión de una variable exógena relevante junto con la capacidad de las redes neuronales para procesar patrones complejos mejoró significativamente la precisión de los pronósticos [10]. De forma similar, revisiones sistemáticas recientes resaltan que muchos trabajos reportan menores errores de predicción al integrar modelos clásicos con algoritmos de aprendizaje automático, en comparación con usar cada enfoque por separado [11], [12]. Esto sugiere que no hay una solución única y universal para la predicción de precios: las estrategias más efectivas podrían ser específicas para cada producto o mercado, combinando diferentes técnicas según la naturaleza de la serie (lineal, altamente volátil, influenciada por factores externos, etc.). Precisamente, el presente proyecto adopta un enfoque integrador, probando tanto modelos estadísticos (ARIMA/SARIMA) como de aprendizaje profundo (LSTM) e incluso un modelo
híbrido propio (denominado LSTMX) que incorpora variables externas, con el fin de identificar cuál es la mejor técnica de predicción para cada producto analizado.
Objetivos Completados
Este proyecto desarrolló un sistema de predicción de precios de la canasta básica dominicana, logrando anticipar variaciones semanales de productos clave con un alto grado de precisión. Para alcanzar este objetivo general, se cumplieron objetivos específicos bajo la metodología SMART: (1) Se recopiló y depuró un histórico amplio de precios y factores económicos relacionados, (2) se implementaron múltiples modelos de series temporales (ARIMA, SARIMA, SARIMAX, LSTM y una variante mejorada LSTMX) ajustándolos con criterio cuantitativo, (3) se evaluó comparativamente el desempeño de cada modelo mediante métricas de error (MAE) identificando la técnica óptima para cada producto, y (4) se desarrolló una API y una interfaz web (AhorraYa) que integran el modelo ganador, brindando pronósticos actualizados y útiles a usuarios finales.
Metodología:
Para abordar el problema de investigación se siguió una metodología estructurada en fases consecutivas, abarcando desde la obtención de datos brutos hasta la implementación de una aplicación funcional. A continuación, se describen las etapas principales del proyecto, destacando las técnicas empleadas en cada una y cómo se fueron integrando para materializar la solución propuesta.

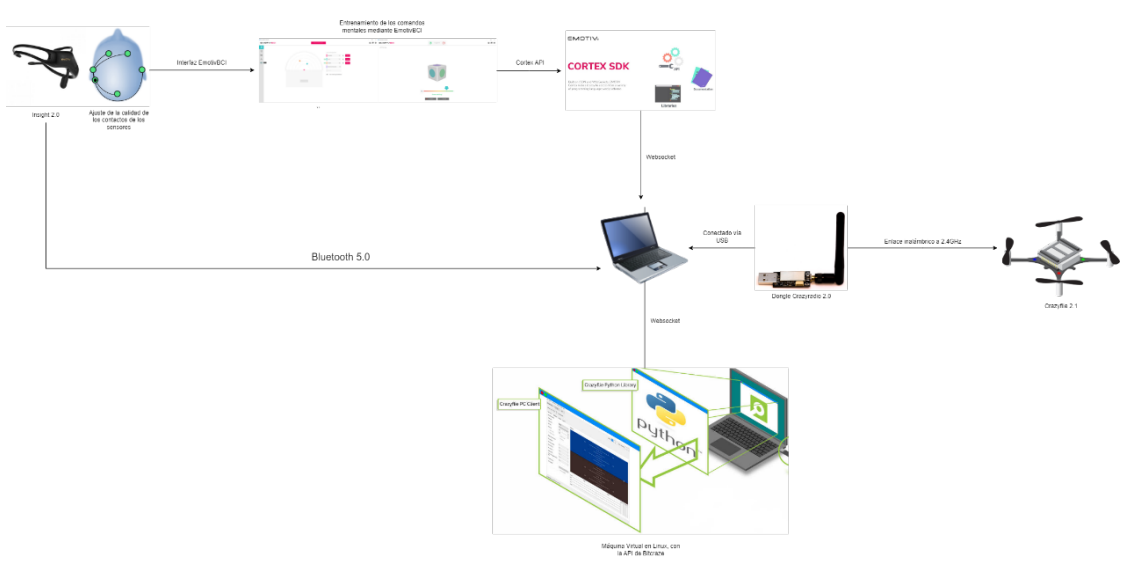
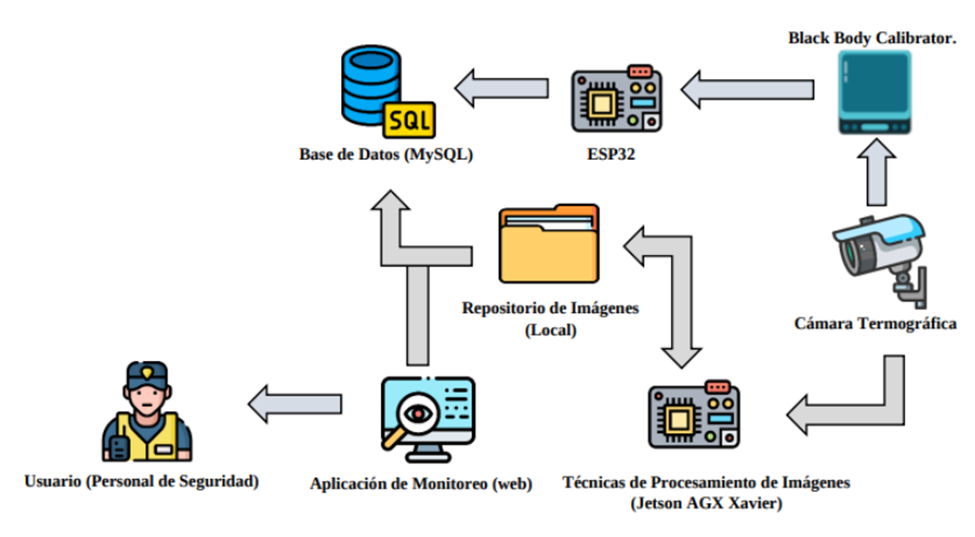
Diagrama de bloques del proyecto.
Este diagrama de arquitectura general ilustra los módulos principales del sistema y su interacción: fuentes de datos, preprocesamiento, análisis/modelado, y componentes de despliegue (API e interfaz). Se observa cómo el Módulo de Adquisición de Datos reúne la información de precios desde distintas fuentes (portales oficiales como ProConsumidor/SIDIP y datos abiertos del gobierno, así como registros del Banco Central para variables económicas). Estos datos alimentan al Módulo de Preprocesamiento, donde se realizan tareas de limpieza, transformación de formatos y consolidación en un dataset unificado. Luego, el Módulo de Análisis y Modelado toma el conjunto de datos limpio para efectuar el análisis exploratorio y entrenar los diversos modelos predictivos. Finalmente, los resultados de los modelos se integran en un Módulo de Servicio de Predicción (API backend) y se presentan al usuario a través de un Módulo de Visualización (interfaz web) desarrollado en Streamlit. A continuación, se detallan cada una de estas fases metodológicas:
- Recolección de datos: Se recopiló un amplio histórico de datos de precios semanales de productos básicos, abarcando varios años para asegurar suficiente información temporal. Las fuentes principales fueron portales oficiales dominicanos que proveen datos abiertos sobre precios: el portal Precios Justos del Ministerio de Industria y Comercio, el conjunto de datos abiertos del gobierno (datos.gob.do, dataset “Precios Justos”), y el Sistema Dominicano de Información de Precios (SIDIP) de Pro Consumidor. Estos portales suministran precios actualizados de diversos alimentos en distintos tipos de establecimientos (supermercados, mercados minoristas, etc.), lo que permitió recopilar series de tiempo por producto y por tipo de mercado. Complementariamente, se incluyeron variables macroeconómicas externas (ej. la tasa de cambio del dólar, el Índice de Precios al Consumidor – IPC) obtenidas de fuentes confiables como el Banco Central y publicaciones económicas, dado que tales factores podrían influir en el costo de los alimentos. Para la extracción de datos se combinaron descargas directas de datasets abiertos con técnicas de web scraping (automatización de la recolección en sitios web), asegurando así la obtención de un histórico completo y confiable. Al finalizar esta etapa se contaba con un conjunto de datos bruto que incluía, para cada fecha semanal, los precios de cada producto en diferentes mercados, junto con valores sincrónicos de variables económicas relevantes.
- Limpieza y preparación de datos: Una vez reunidos, los datos pasaron por un riguroso proceso de preprocesamiento. Esta fase fue crucial, pues la calidad de las predicciones depende directamente de la calidad de los datos de entrenamiento. Se depuraron registros inconsistentes o erróneos, se identificaron y manejaron valores faltantes (imputándolos o eliminándolos según el caso), y se filtraron outliers (valores atípicos) que pudieran distorsionar los análisis. Por ejemplo, si en una semana determinada algún producto mostraba un precio extremadamente fuera de rango debido a un error de captura, dicho dato se inspeccionó y, de ser necesario, se corrigió o descartó. También se homogeneizaron las unidades y formatos: todos los precios fueron convertidos a una unidad estándar (p. ej., RD$ por libra o por unidad, según correspondiera) para hacer comparables las series. En paralelo, las variables externas (tipo de cambio del dólar, IPC, etc.) se alinearon temporalmente con las series de precios, de modo que pudieran integrarse apropiadamente en los modelos posteriores. El resultado de esta etapa fue un dataset estructurado y limpio, listo para el análisis exploratorio y el modelado. Para
asegurar la trazabilidad, se documentaron las transformaciones aplicadas a los datos (por ejemplo, listas de outliers removidos y reglas de imputación).
- Análisis Exploratorio de Datos (EDA): Con los datos ya preparados, se realizó un análisis exploratorio para entender el comportamiento histórico de los precios. Se generaron gráficas de series temporales para visualizar las tendencias generales de cada producto a lo largo del tiempo, identificando periodos de aumentos, descensos y estacionalidades marcadas. Por ejemplo, se pudo notar que el precio del arroz selecto presentaba leves incrementos a finales de cada año (posiblemente ligado a festividades), mientras que el pollo procesado tendía a encarecerse en períodos de alta demanda como las semanas previas a feriados. Adicionalmente, se calcularon estadísticas descriptivas (media, desviación estándar, rangos) para cuantificar la variabilidad de precios de cada producto, y se examinaron correlaciones entre la serie de precios y las variables macroeconómicas. Esto permitió responder preguntas como: ¿el alza del dólar precede aumentos en ciertos alimentos? o ¿algún producto muestra un patrón estacional semanal o mensual? En este punto, también se verificó la estacionariedad de las series –requisito importante para ciertos modelos estadísticos– aplicando pruebas como la de Dickey-Fuller. Por ejemplo, se identificó que varias series tenían tendencia (no estacionarias), por lo que sería necesario diferenciarlas al aplicar un ARIMA. El EDA proporcionó intuiciones clave y validó supuestos de modelado: confirmó la presencia de estacionalidad anual en algunos productos, evidenció tendencias a largo plazo en otros, y ayudó a decidir qué factores externos valía la pena incluir en los modelos (por ejemplo, si la tasa de cambio mostraba correlación significativa con el precio de las habichuelas, eso sugería usarla como variable exógena en un modelo SARIMAX/LSTMX).

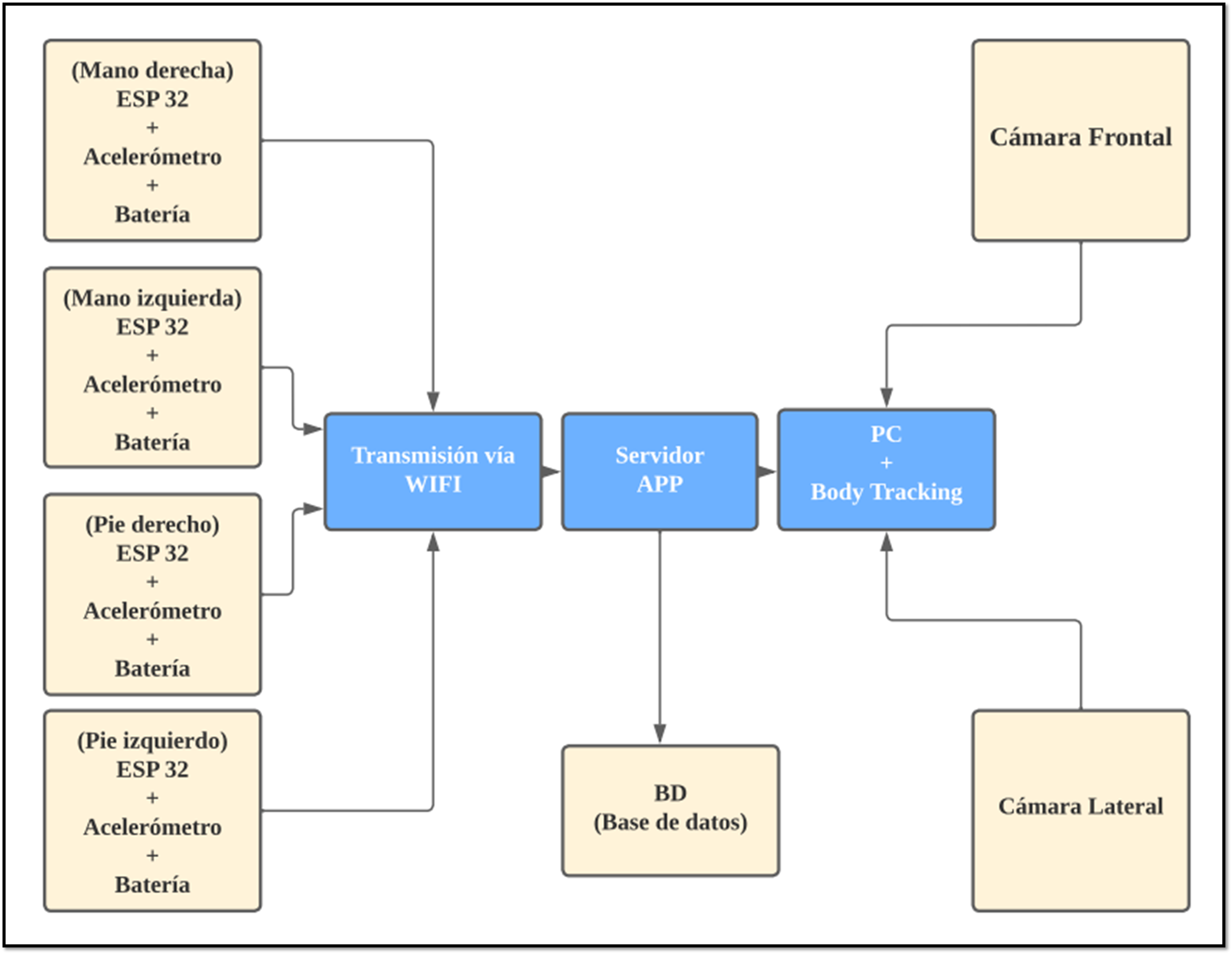
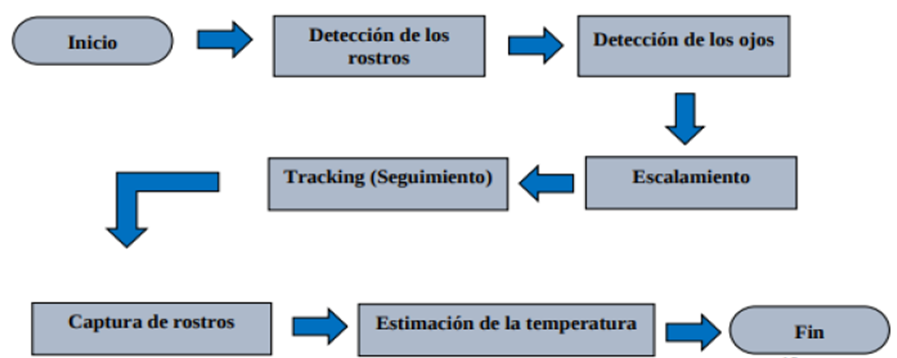
Diagrama de flujo del proceso general.
Este diagrama esquematiza la secuencia de pasos desde la extracción de datos hasta la visualización de resultados. En la etapa de extracción, se combinan los datos de SIDIP vía web scraping, datos de ProConsumidor (en formato PDF procesados con OCR) y la obtención complementaria de información de Precios Justos. Luego, en la Integración y Limpieza del Dataset, se unifican esas fuentes heterogéneas y se preprocesan los datos (como se describió en los pasos 1 y 2). A continuación, en la fase de Análisis y Entrenamiento, se alimentan los datos limpios al conjunto de modelos que se entrenan (ARIMA, SARIMA, SARIMAX, LSTM y LSTMX), realizando también la selección y ajuste de hiperparámetros. Finalmente, los pronósticos resultantes se visualizan en la interfaz Streamlit junto con los datos históricos, completando el ciclo. Este flujo garantiza que, desde la recopilación hasta la presentación, la información pase por etapas bien definidas que agregan valor: de datos crudos dispersos se llega a predicciones accionables para el usuario final.
- Modelado predictivo: En la etapa de modelado se implementaron y probaron diversos algoritmos de series temporales para generar pronósticos de precios, aprovechando las lecciones aprendidas en el EDA. Específicamente, se consideraron cinco enfoques principales: ARIMA, SARIMA, SARIMAX, LSTM y LSTMX. El modelo ARIMA (AutoRegresivo Integrado de Media Móvil) se usó como punto de partida por su eficacia conocida en series estacionarias y su capacidad para modelar patrones autorregresivos e integrados de una serie. Posteriormente, SARIMA (ARIMA estacional) extendió ese modelo incorporando términos estacionales para ajustar periodicidades anuales o mensuales observadas (por ejemplo, permitiendo que el modelo “recuerde” picos cada 12 meses si los hubiera). Por su parte, SARIMAX añadió la posibilidad de incluir variables exógenas –en este caso, factores macroeconómicos como la mencionada tasa de cambio del dólar u otros índices económicos– con la expectativa de mejorar la predicción si dichos factores tienen influencia significativa en los precios. Esta inclusión de variables externas está respaldada por la literatura, que ha mostrado que combinar información exógena en modelos de series de tiempo puede mejorar notablemente el desempeño del pronóstico [10], [11], siempre y cuando exista una correlación o causalidad de Granger entre la variable externa y la serie objetivo. Finalmente, se entrenó un modelo de red neuronal LSTM, apropiado para secuencias temporales complejas, con el fin de capturar patrones no lineales y de largo plazo que los métodos estadísticos tradicionales podrían pasar por alto [6]. Sobre la base de la LSTM, se desarrolló una variante denominada LSTMX, que constituye una contribución novedosa del proyecto: este modelo incorpora las mismas variables exógenas que SARIMAX (por eso la “X”) pero dentro del marco de una red neuronal. En otras palabras, LSTMX es una red LSTM multivariada que recibe como entradas tanto la serie de precios histórica como las series de factores externos (ej. tipo de cambio), permitiéndole aprender relaciones más ricas. La hipótesis detrás de LSTMX es que, al igual que un ARIMAX aprovecha variables auxiliares, una LSTM también puede beneficiarse de ellas para ajustar mejor sus predicciones – algo que investigaciones recientes avalan al mostrar mejoras con enfoques híbridos y multivariados [10], [6].
Cada modelo se entrenó individualmente con los datos históricos de cada producto, reservando una porción de los datos para validación. Para configurar los modelos se siguieron buenas prácticas reconocidas: en ARIMA/SARIMA se identificaron los
órdenes óptimos (parámetros p, d, q y sus análogos estacionales) mediante análisis de autocorrelación (ACF/PACF) y minimización de criterios de información como AIC. En LSTM/LSTMX se experimentó con distintas arquitecturas (número de neuronas, número de capas ocultas) y funciones de activación adecuadas para series de tiempo, empleando técnicas de early stopping y regularización para evitar sobreajuste. La fase de modelado también incluyó la realización de búsqueda en grilla (Grid Search) para ciertos hiperparámetros, con el fin de garantizar que cada modelo estuviera lo mejor ajustado posible. Por ejemplo, se probó en ARIMA un rango de valores para (p,d,q) y se eligió la combinación con menor AIC en la data de entrenamiento, mientras que en LSTM se evaluaron diferentes batch sizes y tasas de aprendizaje, seleccionando aquellas configuraciones que produjeron menor error en la validación. Este enfoque sistemático de ajuste se alinea con recomendaciones de la literatura para obtener modelos robustos [12].
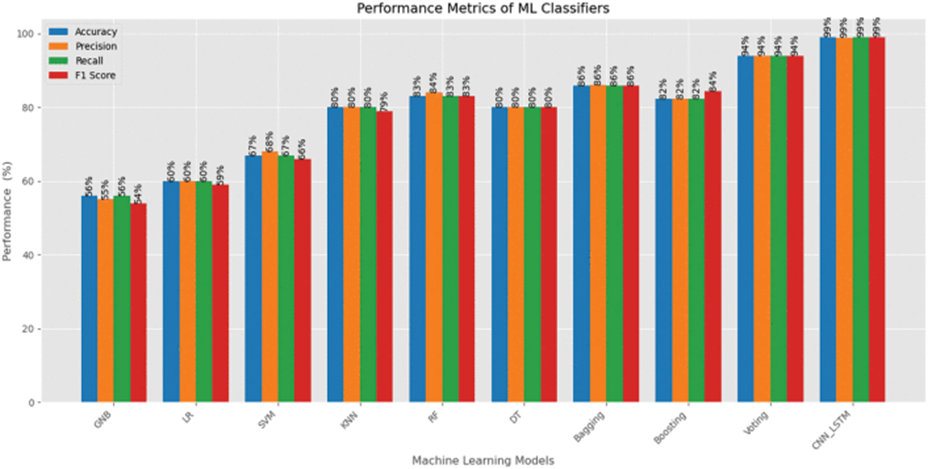
- Evaluación comparativa de modelos: Tras entrenar los modelos, se evaluó su desempeño utilizando métricas cuantitativas de error. La principal métrica empleada fue el Error Absoluto Medio (MAE), por ser fácil de interpretar en unidades monetarias (pesos dominicanos). También se calculó, a modo informativo, la Raíz del Error Cuadrático Medio (RMSE) y el Error Porcentual Absoluto Medio (MAPE) para tener referencias adicionales, aunque el criterio de selección de modelos se basó en el MAE. La evaluación se llevó a cabo en dos escenarios de prueba: primero, usando datos históricos hasta abril de 2025 para generar pronósticos y medir errores (dejando fuera mayo de 2025 como prueba), y luego repitiendo lo mismo extendiendo la historia hasta mayo de 2025 (dejando junio como horizonte de validación). De este modo, se simuló el desempeño del sistema en momentos temporales distintos, comprobando la consistencia de resultados. Para cada producto, se comparó el MAE obtenido por los distintos modelos (ARIMA, SARIMA, SARIMAX, LSTM, LSTMX) tanto en la prueba de abril como en la de mayo. Esta evaluación reveló, por ejemplo, que ciertos productos con comportamientos más lineales se ajustaban bien con modelos ARIMA/SARIMA, mientras que otros con variaciones más erráticas podían ser mejor capturados por la LSTM. En función de los MAE obtenidos en la prueba más reciente (mayo 2025), se seleccionó el modelo “ganador” para cada producto, es decir, aquel con menor error de predicción. De manera ilustrativa, la siguiente gráfica resume los resultados de MAE por modelo para cada producto, destacando cuál técnica resultó más precisa en cada caso.
- Construcción de la aplicación e implementación: Con los modelos optimizados y seleccionados, la fase final consistió en integrar las predicciones en una aplicación práctica para el usuario. Para ello se desarrolló una API backend utilizando FastAPI, que encapsula la lógica de predicción: esta API carga los modelos entrenados (uno por producto, según el mejor identificado por su MAE) y expone endpoints para obtener pronósticos actualizados. La API fue diseñada de tal forma que, dada una solicitud para un producto específico, automáticamente utiliza el modelo óptimo correspondiente (por ejemplo, si el mejor modelo para huevos es LSTM, el API emplea ese; si para pollo es ARIMA, usa aquel otro) y devuelve la predicción de precio para el horizonte deseado (por defecto, la semana siguiente). Sobre esta base, se construyó la interfaz de usuario empleando Streamlit – un marco de desarrollo ágil para aplicaciones de data science. La aplicación web resultante, titulada “AhorraYa”, brinda a los usuarios una experiencia interactiva sencilla: permite seleccionar un producto de interés y consultar su predicción de precio para la próxima semana (o semanas siguientes, según se configure). Además de mostrar el valor pronosticado puntual, la interfaz despliega visualmente la serie histórica reciente junto con la proyección futura, para contextualizar la tendencia. También se incorporó un módulo de reportes automáticos: el sistema puede generar un informe breve que resume las tendencias observadas, el cambio porcentual esperado y alertas en caso de variaciones significativas, el cual podría descargarse en formato PDF o compartirse en redes sociales para beneficio de otros consumidores. Finalmente, AhorraYa incluye una sección de recomendaciones: con base en las predicciones y ciertas reglas sencillas, la aplicación sugiere acciones al usuario para ahorrar o evitar sobrecostos. Por ejemplo, si se anticipa que el precio del pollo aumentará considerablemente la próxima semana, la recomendación podría ser adelantar la compra de ese producto en la semana actual; o si cierto mercado presenta consistentemente precios más bajos para un artículo, la app podría sugerir ese establecimiento como opción de compra. Estas recomendaciones se generan de forma automática e imparcial, buscando guiar al consumidor hacia la decisión más económica e informada posible.

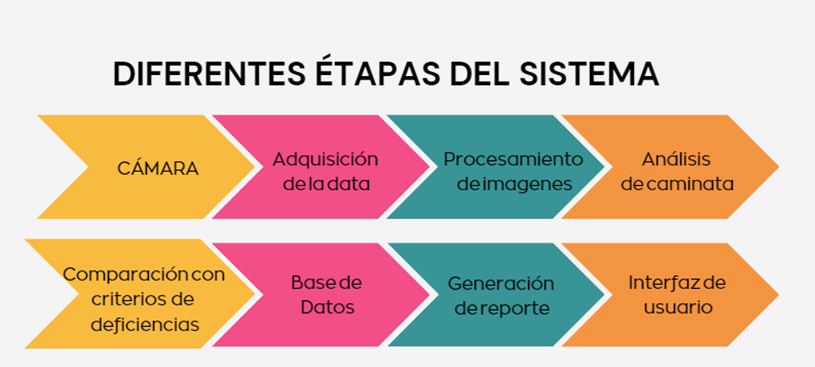
Diagrama de arquitectura de la API.

Diagrama de componentes de la interfaz AhorraYa.
Vale destacar que la arquitectura final del sistema permite su fácil actualización y escalabilidad. Los modelos pueden re-entrenarse periódicamente conforme ingresen nuevos datos (por ejemplo, incorporando los precios más recientes cada mes) y la API puede desplegarse en la nube para atender múltiples consultas simultáneas. La separación en módulos (ver diagrama de bloques) asegura que cada componente pueda mejorarse o reemplazarse independientemente – por ejemplo, se podría actualizar la interfaz sin tocar el backend, o incorporar un nuevo modelo en la API en caso de avances futuros en técnicas de predicción.
La metodología integró desde la obtención de datos brutos hasta la puesta en marcha de una solución tecnológica lista para su uso. Cada fase se apoyó en la anterior para asegurar coherencia y calidad: datos fiables alimentaron un análisis correcto, que a su vez permitió un modelado preciso, culminando en una herramienta práctica y amigable para el usuario. Se logró materializar un pipeline completo de ciencia de datos aplicado a una problemática real, cumpliendo con el objetivo de dotar a los ciudadanos y entidades dominicanas de una forma novedosa de anticipar y enfrentar las fluctuaciones en los precios de los alimentos básicos.
Resultados
Los hallazgos del proyecto son muy alentadores, tanto en las métricas de predicción como en la funcionalidad del sistema final. En cuanto al desempeño predictivo, la estrategia de probar múltiples modelos y seleccionar el más adecuado para cada producto demostró ser acertada. No emergió un “ganador universal”; por el contrario, cada producto básico tuvo una técnica distinta como su mejor pronosticador, lo cual aprovechó al máximo las fortalezas de cada enfoque. Cabe destacar que, en términos generales, todos los métodos evaluados lograron predicciones de alta exactitud (en promedio por encima del 96% de acierto), pero la selección personalizada modelo-por-producto permitió optimizar aún más la precisión en cada caso.
Al analizar detalladamente cada rubro, se observó que los modelos avanzados ofrecieron ventajas marcadas en ciertas series, mientras que en otras los métodos tradicionales fueron igual de efectivos. Por ejemplo, para la habichuela roja –cuyo comportamiento de precios parece depender de factores económicos adicionales– el modelo de red neuronal LSTM que incorporaba indicadores macroeconómicos logró las predicciones más certeras. En cambio, para otro producto como la habichuela negra, un modelo estadístico sencillo (ARIMA) bastó para pronosticar con excelente precisión, señal de que esa serie no presentaba patrones externos o no lineales lo suficientemente fuertes que ameritaran mayor complejidad. Dicho de otro modo, las técnicas de aprendizaje profundo brillaron especialmente cuando la dinámica de precios era compleja o influida por variables exógenas, mientras que en escenarios más estables o lineales un enfoque clásico resultó igualmente competitivo.
La conclusión es clara: no existe una fórmula única que sirva para todos los alimentos, lo cual justifica el enfoque flexible adoptado. Algunos modelos superaron por amplio margen a sus alternativas en ciertos casos, reduciendo el error de pronóstico a una fracción del obtenido por los demás; en otros productos, las diferencias entre técnicas fueron mínimas. Este hallazgo refuerza la importancia de evaluar tanto métodos estadísticos tradicionales como enfoques de aprendizaje profundo, adaptando la solución según las particularidades de cada serie de precios. La siguiente visualización compara de forma resumida el desempeño de todos los modelos probados:

Comparación visual del rendimiento de los modelos por producto. Cada conjunto de barras representa un producto básico (arroz, habichuelas, huevos y pollo), y la barra más baja en cada grupo indica qué modelo logró el menor error de predicción en ese caso. Como se aprecia en la imagen, el método óptimo cambia de un producto a otro, confirmando que ninguna técnica domina en todos los escenarios. También se nota que en algunos alimentos el modelo ganador aventaja claramente a los demás, mientras que en otros las discrepancias de desempeño resultan casi imperceptibles.
Gracias a este exhaustivo análisis, el sistema desarrollado incorpora automáticamente el modelo más adecuado para cada producto en su módulo de predicción. Es decir, cuando un usuario consulta el precio futuro de un alimento –por ejemplo, los huevos– la plataforma emplea en el backend la red LSTM especializada que mejores resultados obtuvo para ese artículo. De igual modo, si se pide la predicción para el pollo, el sistema invoca el modelo específico que demostró ser superior en esa serie (en este caso, una variante de LSTM entrenada con el índice de precios al consumidor). Este mecanismo asegura que la aplicación siempre ofrezca la mejor estimación disponible según nuestros hallazgos, sin que el usuario deba preocuparse por la complejidad técnica detrás.
Importante destacar que los modelos elegidos alcanzaron errores absolutos muy bajos en sus pronósticos. En términos prácticos, la diferencia promedio entre el precio pronosticado y el precio real suele ser de solo unos pocos pesos dominicanos. Dado que en muchos de estos productos una variación semanal típica ronda entre 1 y 5 pesos, un desvío medio de apenas RD$0.5 en las habichuelas o de alrededor de RD$3 en el pollo es lo suficientemente pequeño como para resultar útil en la práctica. En otras palabras, las predicciones fueron tan precisas que el error entra dentro de lo que podría considerarse una fluctuación normal, lo que brinda confianza para la toma de decisiones. Además, el sistema demostró ser capaz de adaptarse y mejorar con el tiempo: al agregar datos más recientes (por ejemplo, un mes adicional de precios) pudo recalibrar sus modelos sin necesidad de reprogramar nada, confirmando la superioridad de ciertos enfoques (como LSTMX en los casos mencionados) simplemente al alimentar la nueva información. Esto indica que la solución puede mantenerse vigente y afinada a medida que se incorporan nuevos datos, algo crucial para su uso en entornos reales cambiantes.
La herramienta resultante, bautizada AhorraYa, está plenamente funcional y pensada para el usuario común. Su interfaz web permite visualizar la serie histórica de precios de cada producto junto con el pronóstico de la semana siguiente en una gráfica interactiva, haciendo muy intuitiva la comprensión de la tendencia. Además, muestra el valor numérico predicho y cuánto varía con respecto al precio actual (por ejemplo: “Se espera que el precio suba 2.3% la próxima semana”), información presentada de forma clara incluso para personas sin formación técnica. Durante las pruebas con usuarios, estos confirmaron que la aplicación es fácil de entender y usar, logrando que los resultados de la predicción sean accesibles para cualquier persona.
También se incorporaron funcionalidades de valor agregado, como la generación automática de reportes en PDF y un módulo de recomendaciones, con el fin de maximizar la utilidad de la herramienta. Por ejemplo, un usuario puede descargar el informe semanal de precios y compartirlo con su comunidad local, mientras que un analista de la entidad reguladora (Pro Consumidor) podría emplear estos reportes para detectar a tiempo comportamientos anómalos en el mercado. Cabe mencionar que la arquitectura modular del sistema probó ser sólida, ya
que la API manejó correctamente múltiples consultas simultáneas y la interfaz se actualiza casi en tiempo real sin inconvenientes. En conjunto, el prototipo está listo para escalarse y funcionar de manera confiable en situaciones reales.
Un resultado particularmente notable fue la mejora obtenida al incorporar variables macroeconómicas en el modelo para ciertos productos. En los casos donde factores como la inflación o el tipo de cambio inciden en los costos (piénsese en algunos granos importados), añadir estos indicadores al modelo permitió reducir aún más el error de predicción, demostrando que esa información adicional fue valiosa. Este hallazgo abre la puerta a integrar en el futuro más fuentes de datos externas –por ejemplo, índices climáticos, precios internacionales de materias primas o costos de combustibles– para potenciar todavía más la precisión de las previsiones en escenarios complejos. Asimismo, se comprobó que los patrones estacionales típicos (por ejemplo, los picos de precios en diciembre) fueron capturados adecuadamente por los modelos que incorporaban estacionalidad, cumpliendo otro de los objetivos iniciales del proyecto. Esto significa que el sistema reconoce las alzas cíclicas esperadas y no se ve sorprendido por ellas, aportando confianza en sus pronósticos durante todo el año.
En resumen, los resultados respaldan plenamente la hipótesis de trabajo original: es posible anticipar –con errores acotados– las variaciones semanales de precios de productos básicos mediante técnicas de series de tiempo. Quedó demostrado que elegir el modelo adecuado para cada producto mejora de forma tangible la exactitud del pronóstico, en comparación con usar una única metodología para todos los casos. Dicho de otra forma, personalizar la estrategia de predicción por tipo de artículo rinde frutos claros en términos de precisión alcanzada.
La utilidad práctica de estas predicciones quedó de manifiesto al presentar el sistema a posibles usuarios finales y a expertos en economía. Las reacciones fueron muy positivas: los consumidores valoraron poder saber hacia dónde podrían moverse los precios la próxima semana, comentando que esa información les ayuda a decidir cuándo comprar (por ejemplo, aprovechar esta semana antes de que un producto suba de precio, o esperar si se anticipa una baja). Por su parte, las autoridades expresaron interés en la herramienta como complemento a sus sistemas actuales de monitoreo, considerando que podría servir para alertas tempranas de situaciones anómalas (por ejemplo, si se pronostica un alza inusual en algún alimento, investigarlo preventivamente antes de que ocurra). Estas impresiones sugieren que, con un refinamiento y validación adicionales, AhorraYa podría convertirse en un apoyo real para la toma de decisiones tanto a nivel micro (hogares) como macro (políticas de mercado). En definitiva, el sistema ha logrado conectar los precios pasados con predicciones futuras para orientar al consumidor sobre el mejor momento de compra, cumpliendo de forma práctica e intuitiva con el objetivo de reducir la incertidumbre en el mercado alimenticio.
Conclusión
En conclusión, el proyecto logró desarrollar con éxito un sistema integral de predicción de precios para productos básicos en República Dominicana, combinando métodos estadísticos tradicionales y técnicas modernas de aprendizaje profundo. Como resultado, se dispone de una herramienta que anticipa las fluctuaciones de precios con un nivel de precisión útil, lo que representa un aporte significativo para distintos actores: los consumidores pueden planificar sus compras con mejor información, evitando los impactos de alzas sorpresivas; los comerciantes y productores pueden ajustar inventarios y estrategias considerando las tendencias pronosticadas; y las autoridades disponen de alertas previas para focalizar inspecciones o medidas de estabilización en caso de incrementos inusuales. El sistema AhorraYa materializa estos logros en una interfaz amigable, democratizando el acceso a la inteligencia de datos sobre precios a cualquier ciudadano con acceso a internet.
El valor de este sistema radica en promover una gestión proactiva frente a la volatilidad de precios. Tradicionalmente, las respuestas eran reactivas (se actuaba después de que el precio subía); con esta solución, se abre la posibilidad de actuar antes del impacto. Por ejemplo, una familia puede decidir comprar ciertos víveres por adelantado si se prevé una subida considerable la próxima semana, o el Ministerio de Industria y Comercio podría preparar acuerdos con suplidores si observa que varios productos mostrarán alzas concurrentes debido a factores estacionales. En términos de transparencia de mercado, contar con predicciones al alcance del público empodera al consumidor y fomenta la competencia, ya que los comercios sabrán que los compradores tienen expectativas informadas y no solo conocerán el precio actual sino su posible trayectoria.
Aunque el proyecto alcanzó sus objetivos, quedan oportunidades de mejora y líneas de trabajo futuras. En primer lugar, sería deseable ampliar el catálogo de productos considerados, incorporando más alimentos de la canasta básica e incluso bienes no alimenticios cuyos precios afectan el presupuesto familiar. Cada nuevo producto requeriría recopilar su serie de precios e integrarla al pipeline ya construido. Adicionalmente, se puede explorar la inclusión de nuevos factores externos que puedan mejorar las predicciones: variables climáticas (lluvias, temperatura) que impactan cosechas, precios internacionales de materias primas relevantes, costos de transporte y combustible, entre otros. Estudios previos indican que incorporar datos meteorológicos puede aumentar la precisión de predicción en horizontes largos [6], por lo que combinar pronósticos climáticos con los de precios agrícolas sería un paso interesante. Otra línea futura es evaluar modelos avanzados emergentes, como las redes neuronales con mecanismos de atención o los modelos tipo Transformers diseñados para series de tiempo, que en años recientes han mostrado potencial en dominios de alta dimensionalidad. Asimismo, se podría implementar un módulo de AutoML que periódicamente pruebe nuevos modelos o re- entrene los existentes para ajustarse a posibles cambios estructurales en las series (por ejemplo, si la dinámica de precios cambia post-pandemia, que el sistema pueda recalibrarse).
En cuanto a la implementación, sería valioso desplegar AhorraYa en un entorno de producción real para recopilar retroalimentación de usuarios y monitorear su uso en el tiempo. Esto permitiría identificar qué funcionalidades adicionales podrían agregarse (por ejemplo,
comparador de precios entre mercados, notificaciones push de alertas de precios, etc.). También sería importante trabajar en estrategias de difusión para que la herramienta llegue a las comunidades que más lo necesitan, en coordinación con instituciones como Pro-Consumidor o el Ministerio de Agricultura.
En definitiva, este proyecto demuestra la viabilidad de aplicar técnicas de análisis de series temporales a un problema concreto de la vida cotidiana dominicana, proporcionando una solución tecnológica innovadora. Los objetivos planteados fueron cumplidos al integrar satisfactoriamente un conjunto heterogéneo de datos, metodologías de modelado de vanguardia y un desarrollo de software enfocado en la utilidad práctica. Si bien el contexto local presenta desafíos (datos a veces escasos, alta volatilidad por factores externos), la combinación adecuada de enfoques permitió sortearlos y entregar un producto funcional. A futuro, con más datos y refinamientos, el sistema podría volverse aún más preciso y abarcar mayor alcance. La anticipación de precios que brinda AhorraYa tiene el potencial de convertirse en una herramienta valiosa para mejorar la planificación económica tanto en los hogares como en las políticas públicas, contribuyendo a mitigar los efectos de la volatilidad en la canasta básica. Queda abierta la invitación a profundizar en esta línea de investigación, incorporando nuevos avances y adaptando la solución a otros ámbitos (por ejemplo, predicción de precios de insumos agrícolas o de energía), en pos de seguir aprovechando la ciencia de datos para el bienestar social.
Referencias:
- U. F. Jayatri et al., “Modelling and Predicting Volatility in Essential Food Prices Using ARIMA-GARCH Models,” Efficient: Journal of Industrial Engineering, vol. 1, no. 1, pp. 41– 64, 2024.
- J. G. da Silva, “Discurso sobre la volatilidad de los precios de los alimentos y el papel de la
especulación,” FAO, Roma, 6 de julio de 2012.
- Pro Consumidor, “¿Qué es SIDIP? – Sistema Dominicano de Información de Precios,” [En línea]. Disponible: https://proconsumidor.gob.do/que-es-sidip
- V. Jadhav, B. V. Chinnappa Reddy, and G. M. Gaddi, “Application of ARIMA Model for Forecasting Agricultural Prices,” J. Agr. Sci. Tech., vol. 19, pp. 981–992, 2017.
- Z. Yang et al., “Pork Price Prediction using LSTM Model: Based on a New Dataset,” Proc. 1st Int. Conf. Public Management, Digital Economy and Internet Technology (ICPDI), pp. 423–429, 2022.
- M. Elsaraiti and A. Merabet, “A Comparative Analysis of the ARIMA and LSTM Predictive Models for Wind Speed,” Energies, vol. 14, no. 20, Art. 6782, Oct. 2021.
- C. Xia, “Comparative Analysis of ARIMA and LSTM Models for Agricultural Price Forecasting,” Highlights in Science, Engineering and Technology, vol. 85, pp. 1032–1040, 2024.
- S. Hochreiter and J. Schmidhuber, “Long Short-Term Memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997.
- D. A. Dickey and W. A. Fuller, “Likelihood Ratio Statistics for Autoregressive Time Series
with a Unit Root,” J. Am. Stat. Assoc., vol. 74, no. 366, pp. 427–431, 1979.
- P. Pandit et al., “Hybrid time series models with exogenous variable for improved yield
forecasting of crops,” Sci. Reports, vol. 13, Art. 22240, 2023.
- A. Theofilou et al., “Predicting Prices of Staple Crops Using Machine Learning: A
Systematic Review,” Sustainability, vol. 17, no. 12, Art. 5456, 2025.
- K. G. Preetha et al., “Price Forecasting on a Large Scale Data Set using Time Series and Neural Network Models,” KSII Trans. Internet Info. Syst., vol. 16, no. 10, pp. 3923–3942, 2022.